

Le prochain échelon de l'échelle du GPU
Si vous gérez des tâches liées à l'IA, vous savez déjà dans quelle mesure votre choix en matière de matériel détermine ce qui est possible et quel en est le coût. C'est pourquoi nous avons ajouté la NVIDIA RTX 5090 à Compute. Plus de rapidité, moins d'attente et un juste prix. Passons directement aux chiffres.
Pourquoi le 5090 rejoint la gamme
Lorsque nous l'avons lancé avec les 4090, cela a résolu un gros problème : les GPU pour centres de données tels que l'A100 étaient soit impossibles à obtenir, soit très chers. Le 4090 s'est avéré être le point idéal pour la plupart des charges de travail d'inférence LLM et d'IA.
Mais nos utilisateurs nous ont poussés plus loin. Les équipes souhaitaient une inférence plus rapide, une meilleure mise à l'échelle et une option permettant de passer à « tout » sans consommer d'énergie. Lorsque le premier lot de 5090 est arrivé, nous l'avons testé et avons ouvert une toute nouvelle région (UAE-2) afin que vous puissiez y accéder immédiatement.
Les points forts des benchmarks en un coup d'œil
Nous avons effectué des tests côte à côte en utilisant de véritables charges de travail LLM. Voici ce qui se démarque :
- 5090 barres obliques de bout en bout latence jusqu'à 9,6 fois par rapport à la 4090, et plus que le double de la vitesse de l'A100.
- À des charges élevées, le 5090 fournit près de 7 fois débit du 4090 et plus de 2,5 fois le débit de l'A100.
- Chaque 5090 utilisations énergie plus judicieusement, offrant des performances par watt plus de trois fois supérieures à celles du 4090.

Si vous gérez des LLM de petite ou moyenne taille, le 5090 est désormais l'option la plus rapide et la plus rentable en matière de calcul.
Comment nous avons effectué les tests
Nous ne nous cachons pas derrière des repères que personne ne peut reproduire. Voici notre configuration :
- Modèle : meta-lama 3.1-8B-Instrut
- Taille du lot : Contexte 8 192 ; sortie 512 jetons
- Moteur : vLLM 0.8.3 (benchmark_serving.py)
- Scénarios :
- Charge modérée (1 reque/s, 100 invites)
- Charge extrême (1 100 reques/s, 1 500 invites)
- Régions : France, Émirats arabes unis 2
Vous pouvez consulter les résultats détaillés dans notre PDF de référence. Si vous souhaitez examiner de plus près les configurations de test ou si vous souhaitez effectuer vos propres comparaisons, il vous suffit de demander. Nous sommes heureux de vous expliquer les détails.
Ce que cela signifie pour votre charge de travail
Avec les 5090, toute personne utilisant des LLM dont les paramètres ne dépassent pas 13 milliards de paramètres peut bénéficier des performances de son centre de données, sans avoir à payer de facture ni à attendre six mois. Les cartes sont mises à l'échelle linéaire, ce qui vous permet de les regrouper et de gérer de lourdes charges de travail, ou d'en créer une pour des expériences rapides.
- Pour la plupart des tâches d'inférence, vous bénéficierez d'une latence plus faible et d'un meilleur rapport prix/performances que n'importe quelle option de calcul précédente.
- La facturation à la seconde permet de maintenir des coûts honnêtes, sans frais supplémentaires ni surprises.
Quand les 4090 ou les A100 gagnent encore
Tous les travaux n'ont pas besoin du plus gros marteau. Voici quand le 4090 ou l'A100 pourrait être votre meilleur choix :
- Si vous vous entraînez avec de grands modèles et que vous avez besoin de plus de VRAM que ne le propose un 5090, les nœuds A100 ont toujours du sens.
- Pour les tâches comportant des séquences très longues ou des réglages précis sur plusieurs cartes, les A100 brillent.
- Le 4090 reste une valeur incroyable pour les petits projets ou les budgets serrés.
Néanmoins, nous pensons que dans la plupart des cas d'utilisation, les 4090, et maintenant les 5090, constituent un meilleur choix que les A100. Consultez notre article précédent Pourquoi de plus en plus de développeurs choisissent le RTX 4090 au lieu de l'A100 pour en savoir plus.
Comment lancer un 5090 dans Compute
C'est toujours aussi simple :
- Connectez-vous à votre Calculer tableau de bord
- Choisissez un région
- Sélectionnez PROCESSEUR GRAPHIQUE (5090) en tant que matériel
- Choisissez votre modèle (ou créez le vôtre)
- Cliquez Lancement
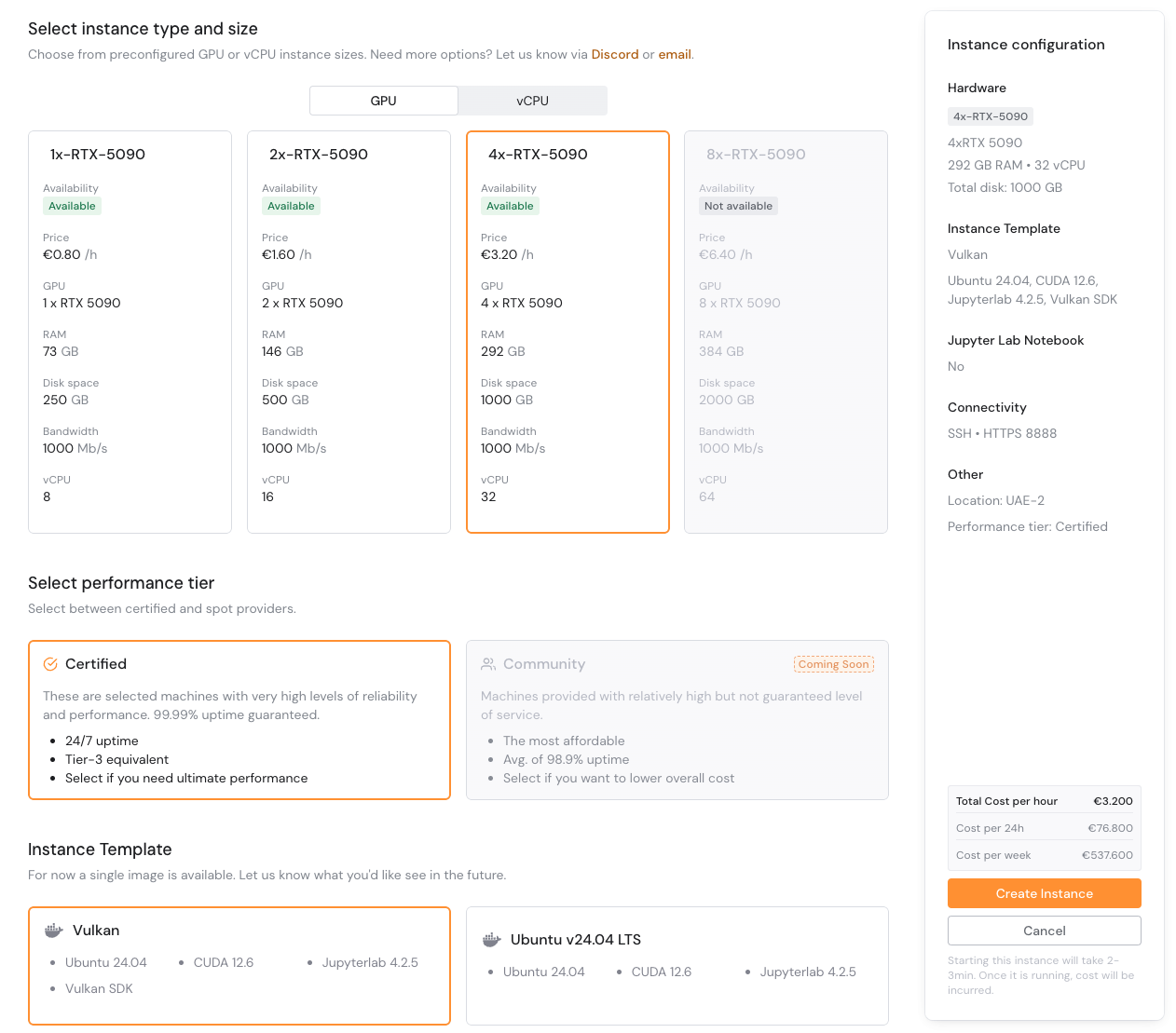
Vous êtes opérationnel en moins d'une minute.
Perspectives d'avenir
Nous prévoyons déjà d'autres régions avec une capacité de 5090 et testons des modèles multi-GPU. Si vous avez des commentaires ou si vous souhaitez une fonctionnalité, faites-le nous savoir. L'informatique évolue en permanence avec vous.
